The story of how software are created in a lab
Article created following my presentation to the Research Software Engineer day in Belgium.
BLOG


When I was invited to speak at Belgium RSE 2024, I had a theory in mind that I wanted to share and explore with others. This theory revolves around how software is created in academic labs.
Over the last five years, I’ve had the opportunity to work with several labs and engage in discussions with many more. A recurring pattern began to emerge—a familiar story of how software originates in these environments. Often, the process starts as a side project undertaken by PhD students, postdocs, or occasionally even principal investigators.
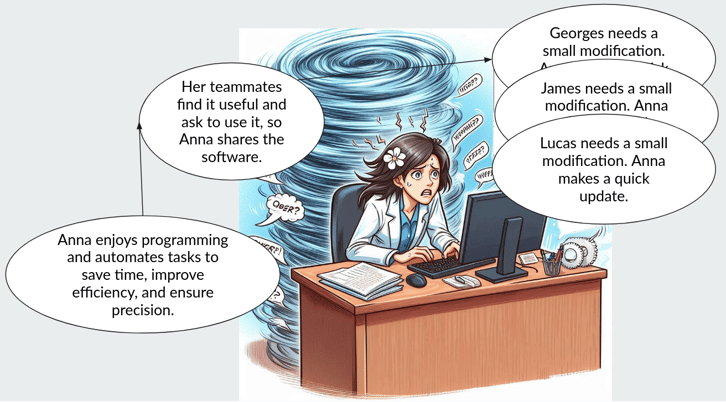
It typically begins with someone passionate about programming who sees an opportunity to streamline or enhance their own work. Once the tool proves useful, it doesn’t take long for it to spread within the lab, with others adopting it for their projects.
At first, everyone is happy. The tool works well, and people in the lab benefit from its efficiency. But very quickly, the burden of responsibility falls entirely on the original programmer. They are expected to handle everything—maintaining the software, developing new features, fixing bugs, troubleshooting, and even assisting with installations on other machines.
What began as a side project suddenly grows into a full-time commitment, but without the necessary time or funding to support it. In an attempt to meet the increasing demands, the developer often resorts to quick fixes, sacrificing best practices and long-term maintainability.
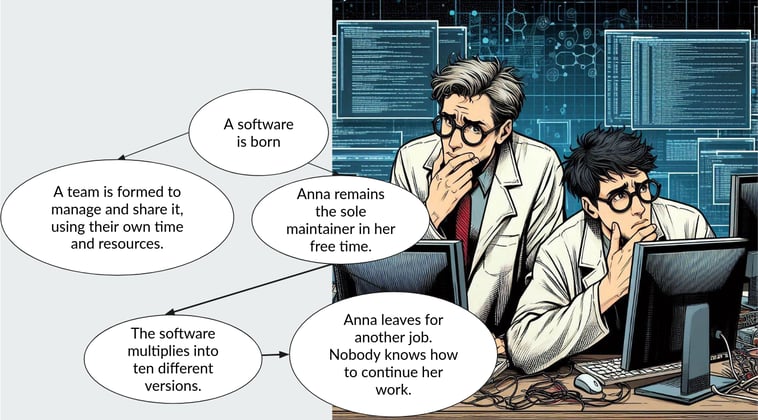
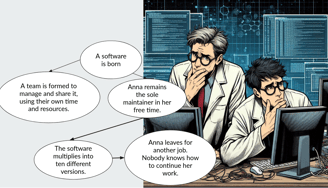
At this point, we can say that a software project is truly born. Two scenarios typically follow:
In the first, a dedicated team is formed to work full-time on the project. This is often the case for successful initiatives with significant backing, such as DeepLabCut, SpikeInterface, or Open-Ephys. These projects benefit from having resources, structure, and long-term sustainability.
In the second scenario, however, the responsibility remains with a single maintainer. This often leads to challenges: the software may fragment into multiple divergent versions, each tailored to specific users but difficult to reconcile. Users might wish they could combine these versions into a cohesive tool, but the effort is often too great. Alternatively, the sole maintainer may leave, and with them, the knowledge of how to manage or evolve the software—leaving the project abandoned and unusable.

Lately, I’ve found myself stepping into projects as a freelance developer at this exact stage—when the software has splintered into irreconcilable versions, and no one is quite sure how to move forward. It’s a challenge I enjoy, and I’ve become quite effective at rapidly diagnosing and fixing these issues.
If this story resonates with you, and you’re facing a similar situation, don’t hesitate to reach out. I can help bring your software back to a point where it works seamlessly, bringing back the simplicity and efficiency that once made everyone happy—and allowing your team to focus on advancing their research.